|
> Mínimos quadrados ponderados (WLS): Se a distribuição dos resíduos não é constante, os erros padrão estimados não serão válidos. Em vez disso use Mínimos Quadrados Ponderado para estimar o modelo (Por exemplo, quando for prever valores de ações, ações de maior valor oscilam mais que ações de menor valor).
> Mínimos Quadrados em Dois Estágios (2LS): Use essa técnica para estimar sua variável dependente quando as variáveis independentes são correlacionadas com os termos de erro de regressão.Por exemplo, um clube do livro pode querer modelar a quantidade de venda cruzada para membros usando o valor que os membros gastaram em livros como um preditor. No entanto, o dinheiro gasto em outros itens é um dinheiro não gasto em livros, assim uma melhora nas vendas cruzadas corresponde a uma queda nas vendas de livros. A Regressão Mínimos quadrados em dois estágios corrige este erro
> Análise de probito: A análise de probito é a mais apropriada quando você deseja estimar os efeitos de uma ou mais variáveis independentes em uma variável categórica dependente. Por exemplo, você poderia usar a análise de probito para estabelecer a relação entre o percentual de desconto de um produto e se um consumidor comprará de acordo com essa queda do preço. Então para cada percentual dado de desconto, você pode calcular a probabilidade do cliente comprar o produto.
> O IBM SPSS Regression inclui diagnósticos adicionais para se usar quando estiver desenvolvendo um tabela� de classificação.
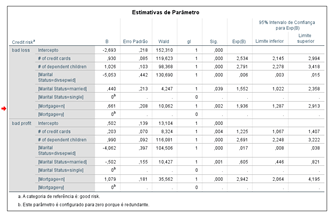
O procedimento regressão logística multinomial prevê um resultado categórico como “razão principal para análise de crédito”. As categorias nesse exemplo são: a) Marital - estado civil, b)Mortage - Tem hipoteca, C) credit cards - número de cartão de crédito e d)dependente children - número de filhos. A partir dos resultados acima, nós podemos ver que aumentando o número de filhos aumenta a chance do cliente ter um risco de crédito alto comparado com um cliente que possui um risco de crédito aceitável.
|
Mais estatísticas para a análise de dados
Expanda as capacidades do IBM® SPSS® Statistics Base para o estágio de análise de dados no processo analítico. Usar o IBM SPSS Regression com o IBM SPSS Statistics Base lhe dá uma gama ainda maior de estatísticas, assim você pode conseguir as respostas mais precisas para tipos específicos de dados.
O IBM SPSS Regression inclui:
> Regressão logística multinomial (MLR): Realize a regressão de uma variável dependente categórica com mais de duas categorias em um conjunto de variáveis independentes. Esse procedimento ajuda a prever com precisão membros nos principais grupos. Você também pode utilizar a análise stepwise, para encontrar o melhor conjunto de preditores entre dezenas de possíveis preditores. Se você tem um grande número de preditores, os métodos Score e Wald podem ajudar a alcançar resultados mais rapidamente. Você pode acessar o ajuste do seu modelo usando o critério de informação de Akaike (AIC) e o critério de informação bayesiano (BIC; também chamado de critério bayesiano de Schwarz, ou SBC).
> Regressão logística linear: Agrupe pessoas com relação a suas ações previstas. Utilize esse procedimento se você precisar construir modelos nos quais a variável dependente é dicotômica (por exemplo, comprar versus não comprar, bom pagador versus mal pagador, graduar-se versus não graduar-se). Você ainda pode usar a regressão logística binária para prever a probabilidade de acontecimentos como respostas a solicitações ou participação em programas. Com a regressão logística binária, você pode selecionar variáveis usando seis tipos de métodos stepwise, incluindo métodos progressivos (o procedimento seleciona as variáveis mais fortes até que não ha ja mais preditores significantes no conjunto de dados) e regressivos (a cada passo, o procedimento remove o preditor menos significante no conjunto de dados). Você também pode configurar critérios de inclusão e exclusão. O procedimento produz um relatório relatando a ação tomada em cada passo para determinar suas variáveis.
> Regressão não linear (NLR) e regressão não linear restrita (CNLR): Estime equações não lineares. Se você está trabalhando com modelos que tem relações não lineares, por exemplo, se você está prevendo o resgate de vales como uma função do tempo e número de vales distribuídos, estime equações não lineares usando um dos dois procedimentos do IBM SPSS Statistics: regressão não linear (NLR) para problemas não restritos e regressão não linear restrita (CNLR) para ambos os problemas, restritos e não restritos. A NLR permite estimar modelos com relações arbitrarias entre variáveis independentes e dependentes usando algoritmos de estimação iterativos, enquanto a CNLR permite:
>> Usar restrições lineares e não lineares em qualquer combinação de parâmetros
>> Estimar parâmetros minimizando qualquer função de perda (função objetiva)
>> Calcular estimativas bootstrap da correlação e erro padrão dos parâmetros |









